
30 Jahre Disruption bei der Internet-Suche. Vom schwarzen Lycos-Hund über Google und darüber hinaus. Wie KI die Internetsuche verändern wird.>
Titelbild: Der Lycos-Hund und Frau Google schlürfen einen Martini-Cocktail
007-Fans erkennen den Fehler sofort: heißt es doch “geschüttelt, nicht gerührt”? Glaubt man James Bond, mag das stimmen; Kenner des Martini-Cocktails wissen es besser:
Bei Martini muss man unterscheiden: Es gibt den Martini-Cocktail, der in der Regel aus Gin und Wermut besteht. Der Martini-Cocktail per se hat aber nichts mit der Wermut-Marke Martini zu tun. Ein Martini-Cocktail gehört immer gerührt, es gehört weder eine Zitronenscheibe hinein, noch wird er in ein Weinglas geschenkt.
In diesem Artikel geht es darum, wie uns in den letzten Jahrzehnten der Internet-Cocktail präsentiert wurde.
Die Zeit vor den Webbrowsern
Meine erste Begegnung mit dem Internet fand statt, bevor es Webbrowser gab. In den frühen1990er Jahren gab es CompuServe. Der US-Internetdienstanbieter wurde bereits 1969 gegründet, wuchs in den 1980er Jahren zum weltweit grösten Online-Portal an und war in den 1990er Jahren ein wichtiger Wegbereiter für die Nutzung des Internets in Privathaushalten.
 CompuServe – Bildquelle: https://fudzilla.com/news/44961-compuserve-groups-finally-die
CompuServe – Bildquelle: https://fudzilla.com/news/44961-compuserve-groups-finally-die
Das Internet an sich war dort nur eine Kategorie unter vielen anderen. Es gab auch keine Suche, sondern Inhalte, die wie in einem Branchenbuch gegliedert waren: News, Wetter, Medien, Computer Support, Bildung, Sport, usw. Darunter befanden sich kuratierte Kataloge von Internetseiten.1998 wurde CompuServe durch den früheren Konkurrenten AOL übernommen.
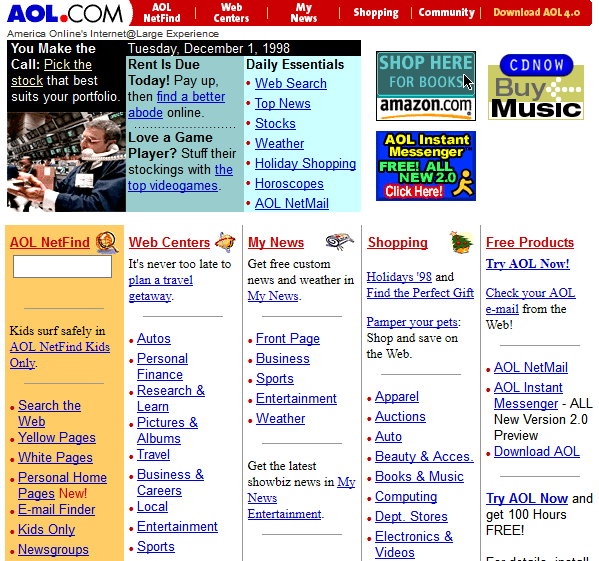 AOL – Bildquelle: https://www.webdesignmuseum.org/gallery/aol-1998
AOL – Bildquelle: https://www.webdesignmuseum.org/gallery/aol-1998
Sowohl CompuServe als auch AOL waren eigenständige Anwendungen, die keinen Internetbrowser benötigten. Bei beiden bezog sich die Suche auf die eigenen Kataloge von Internetseiten.
Die Zeit vor Google
Am 11. November 1993 erblickte der erste Webbrowser das Licht der Welt. Er hiess Mosaik und war für X-Window-Systeme gedacht. Bereits einen Tag später folgte die Bereitstellung von Version 1.0 für Microsoft Windows. Das war auch das Ende der eigenständigen Internet-Anwendungen wie CompuServe und AOL.
Nun erschienen erste Suchmaschinen, die nicht auf kuratierten Internetverzeichnissen aufbauten, sondern Crawler einsetzten, um die exponentiell steigende Anzahl von Internetseiten zu durchsuchen. Zu dieser Zeit entstanden auch die ersten Ranking-Algorithmen. Bekannte Vertreter dieser Suchmaschinen waren: Lycos, AltaVista und Yahoo.
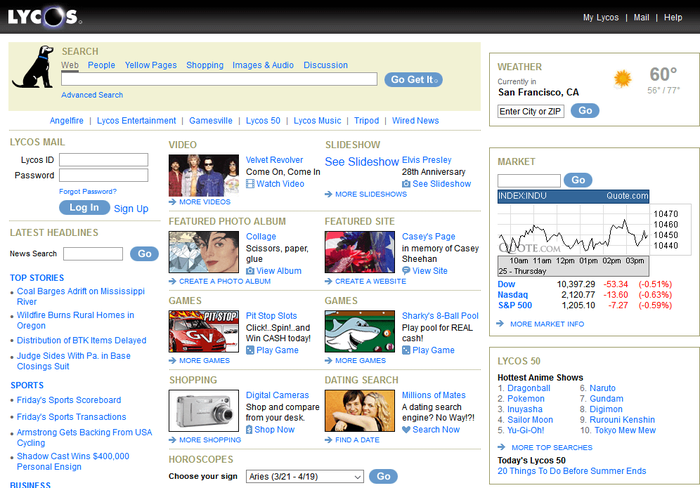 Lycos – Bildquelle: https://www.webdesignmuseum.org/gallery/lycos-2005
Lycos – Bildquelle: https://www.webdesignmuseum.org/gallery/lycos-2005
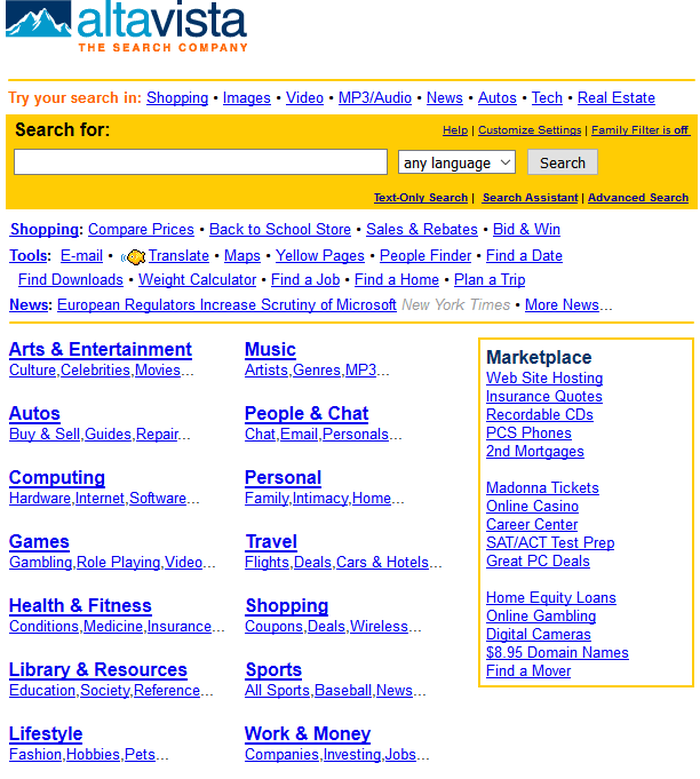 AltaVista – Bildquelle: https://www.webdesignmuseum.org/gallery/altavista-2001
AltaVista – Bildquelle: https://www.webdesignmuseum.org/gallery/altavista-2001
Insbesondere bei AltaVista-Screenshot sieht man, dass die Freitextsuche ganz oben positioniert ist, die Kataloge jedoch immer noch eine Rolle spielen; wenn auch eine untergeordnete.
25 Jahre Google
Bereits zwei Jahre nach der Firmengründung gelang Google im Jahr 2000 der Durchbruch zur beliebtesten Suchmaschine. Der große Unterschied zu den bisherigen “Internet-Katalogen” war die ausschließliche Ausrichtung auf die Suche. Bei Google gab es nie Kataloge, was einen Paradigmenwechsel bedeutete.
Statt selbstständig in einer Auswahl von Internetseiten die passenden auszuwählen, konnte man jetzt eine Frage stellen, worauf einer der die passenden Internetseiten in einer Liste präsentiert wurden. Aufgrund der gigantischen Anzahl von Internetseiten lag dieser Schritt nahe. Google hat dir aus der Fülle des Angebots, die relevanten Seiten in Listenform angeboten. Was zunächst gut funktionierte, wurde durch die gewinnorientierte Ausrichtung der Firma Google zunichte gemacht. Ab 2010 zählte nicht mehr das Informationsbedürfnis der Anwender:innen, sondern das Gewinnstreben der Anbieter von Inhalten. Der Kundenmarkt wurde zu einem Anbietermarkt. Durch Tracking wurde der Kunde zum Produkt.
Google hatte verstanden, wie man die normalen Internet-Anwender:innen maximal ausbeutet, um das Gewinnstreben von Werbekunden und Shareholdern optimal zu bedienen. In der Folge wurde das inoffizielle Credo “don’t be evil” aufgegeben. Nach 2010 hat Google das Internet (wie es einmal gedacht war) systematisch verändert, bestimmt und letztendlich zerstört. Die Zentralisierung und Monopolisierung von fast allen Inhalten und Mechanismen (Werbung, Tracking, Suche, Standards, Browser, Betriebssysteme, Bibliotheken, Algorithmen, Videos, News, Office-Anwendungen, E-Mail usw.) hat Google heute in den Zustand des Römischen Reichs gebracht: Nach dem Hochmut kommt der Fall.
Gemäss meiner Wahrnehmung befindet sich Google am selbst verursachten Abgrund. Vermutlich liege ich mit meiner Einschätzung falsch. Wir werden sehen, ob die Firma sich an sich selbst verschluckt oder ob sie durch staatliche Regulierung zerschlagen wird.
Störung bei der Internetsuche im Laufe der Zeit
1990 – Kataloge von Internetseiten
2000 – Suche nach Internetseiten
2010 – Empfehlung von Inhalten
2025 – KI-gestützte Antworten und Handlungen
2030 – Bedürfnisorientierte Anweisungen
Die Zeit nach Google
Ab sofort wird nicht mehr gerührt, sondern nur noch geschützt. Was meine ich damit? Man kann Internetinhalte ordentlich zusammenrühren, wobei die Zutaten erhalten und erkennbar bleiben. Bei den Katalogen aus den 90er-Jahren war das ohnehin der Fall, aber auch bei den Suchergebnissen, wie wir sie bis heute kannten. Bisher hatte man eine mehr oder weniger gut gerührte Auswahl. Bei der Google-Suche ist diese Auswahl seit ca. 15 Jahren durch Suchmaschinenoptimierung und bezahlte Werbeplätze auf der ersten Seite ziemlich falsch gemischt.
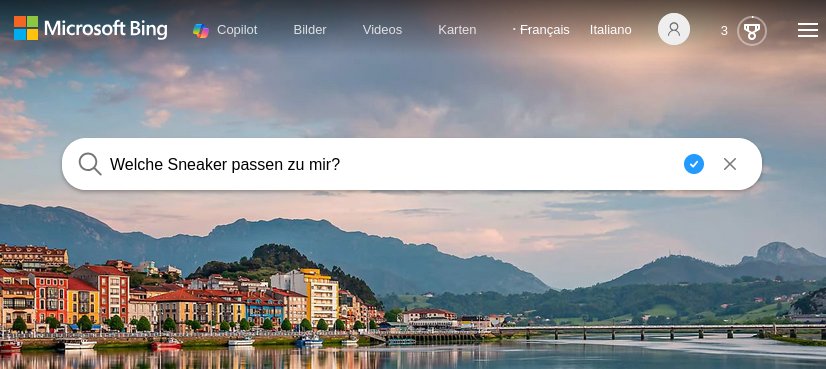
Doch jetzt beginnt eine neue Ära. Viele Anwender:innen verwenden KI-Chatbots wie ChatGPT, Perplexity, Gemini usw. lieber, als die Google-Suche, Microsofts Bing oder andere (klassische) Suchmaschinen. Dieses Momentum möchten die Suchseiten nicht verpassen. Bing prescht hier vor:
- Es geht die Wahl verloren, welchen Webinhalt man glauben schenkt.
- Niemand verfolgt die Quellenangaben, falls sie überhaupt existieren oder korrekt sind.
- Den für das Training verwendeten Webseiten wird die Aufmerksamkeit gestohlen, weil es keinen Grund gibt, dort hinzuklicken.
- Die “geschüttelten” Antwort sieht man nicht an, ob sie wahr oder halluziniert ist, weil sie immer sehr überzeugend geschrieben ist.
- Die Lieferanten des Trainingsmaterials werden (in der Regel) weder gefragt noch vergütet.
- Falsche Antworten sind kaum bzw. nicht reparierbar, was an der Architektur der künstlichen neuronalen Netzwerke liegt.
- Der Energieverbrauch einer KI-Abfrage ist markant höher als bei einer klassischen Suche.
- Wer KI-Chatbots als Universalmaschine für alle Antworten verwendet, verliert die Fähigkeit zur eigenen Informationsrecherche.
Aus Antworten folgen Handlungen
Die Agenten stecken zwar noch in den Kinderschuhen, lassen sich jedoch bei manchen KI-Chatbots schon verwenden. Übliche Beispiele sind die Tischreservierung in einem Restaurant oder das Buchen einer Urlaubsreise. Dass man dem Bot dafür weitgehende Rechte einräumlumen muss, versteht sich von selbst. Solche Agententätigkeiten im Freizeitbereich lassen uns schmunzeln. Wer ist schon so blöd, einem KI-Agenten Zugriff auf sein Konto zu gewähren, um die Urlaubsreise bezahlen zu können? Doch im Büroumfeld sind die Agenten bereits angekommen. Da suchen die Agenten Termine für Sitzungen, laden die Teilnehmer ein und schreiben selbstständig E-Mails. Dabei ist zu bedenken, dass die KI-Bots sich immer über die Identität der Anwender:in im Klaren sind. Das wird als Notwendigkeit und Vorteil verkauft, um eine lernende und sich optimierende Unterstützung anzubieten zu können. Irgendwann haben die KI-Modelle genügend Informationen über dich, sodass der nächste Schritt ansteht.
Bettürfnisorientierte Anweisungen
Ich weiß nicht, wann es soweit sein wird, aber irgendwann hat es sich ausgefragt. Warum sollte ich den KI-Chatbot etwas fragen, wo er doch selbst weiß, was ich fragen möchte, bzw. was meine Routinen und Bedürfnisse sind. Das KI-Modell kennt die Ferienzeiten, meinen Kalender, den Gesundheitszustand, frühere Urlaubsreisen und meine Vorlieben. Auch wird dich der Bot rechtzeitig darauf hinweisen, dass du am 4. August für 2 Wochen Wanderferien auf Korsika machen wirst, weil du dort bisher nicht warst und weil Wandern gut für deine gesundheitliche Situation ist. Selbstverständlich ist bereits alles gebucht und bezahlt. Auch dann: Ausführen! Der KI-Bot möchte keine Widerworte hören. Dafür gibt es bei der Ankunft im Hotel einen Martini-Cocktail zur Begrüssung – geschüttelt, nicht gerührt.
Titelbild: KI-generiert und nachbearbeitet
Quellen:
https://de.wikipedia.org/wiki/Compuserve
https://de.wikipedia.org/wiki/AOL
https://de.wikipedia.org/wiki/NCSA_Mosaic
https://de.wikipedia.org/wiki/Lycos_Europe
https://de.wikipedia.org/wiki/AltaVista
https://de.wikipedia.org/wiki/Yahoo_(Webportal)

